告别手工建广告!用飞书表格+Java打造小红书广告投放神器 发表于: 2025.11.06 | 分类于: 后端 | 阅读次数: 354 ## 背景 你是否遇到过这样的场景:营销团队需要在小红书投放数百个广告计划,每个计划包含多个单元和创意,如果手工在后台一个个创建,不仅效率低下,还容易出错。今天,我们就来聊聊如何用技术解决这个痛点,打造一个**广告批量创建神器**。 ## 一、业务痛点:广告投放的"重复劳动" 在数字营销领域,广告投放人员经常面临这样的困境: - 📊 **批量创建需求高**:一次投放活动可能需要创建几十甚至上百个广告计划 - 🔄 **重复操作多**:计划→单元→创意,三级结构需要反复填写相似的配置 - ❌ **错误率高**:手工操作容易遗漏字段或填错参数 - ⏱️ **时间成本大**:一个完整的广告计划创建可能需要5-10分钟,批量操作更是噩梦 **有没有一种方式,能让投放人员像填Excel一样轻松地批量创建广告?** 答案是:**有的!** ## 二、解决方案:飞书表格 + 后端服务的完美组合 ### 2.1 整体架构设计 我们设计了一个"广告助手"系统,核心思路是: ``` 飞书电子表格(数据输入) ↓ 后端服务(数据验证与转换) ↓ 小红书广告API(批量创建) ↓ 飞书电子表格(结果回写) ``` **为什么选择飞书表格?** 1. ✅ **用户友好**:投放人员熟悉表格操作,学习成本低 2. ✅ **可视化强**:支持下拉选择、数据校验、错误提示 3. ✅ **协作便利**:团队成员可以实时协作编辑 4. ✅ **API完善**:飞书提供了强大的OpenAPI,便于集成 ### 2.2 核心功能实现 #### **功能1:一键创建飞书模板表格** ```java // 创建三个Sheet页 // 1. 主表格:计划-单元-创意信息 sheetId = FsHelper.createBuilder(title, spreadsheetToken, RedBookCreateCascadeInfoDTO.class) .includeColumnField(fields) // 根据模板动态生成列 .fieldDescription(fieldDescriptions) // 添加列说明 .addCustomProperty("advertiserId", advertiserId) .build(); // 2. 关键词表:单独管理关键词配置 keywordSheetId = FsHelper.create("关键词", spreadsheetToken, RedBookKeywordTemplateDTO.class); // 3. 人群优投表:单独管理人群包配置 premiumSheetId = FsHelper.create("人群优投", spreadsheetToken, RedBookPremiumTargetCrowdTemplateDTO.class); ``` **亮点**: - 🎯 根据不同的投放模板动态生成表格结构 - 📝 每列都有详细的说明文档,降低填写难度 - 🔒 关键字段支持下拉选择,避免输入错误 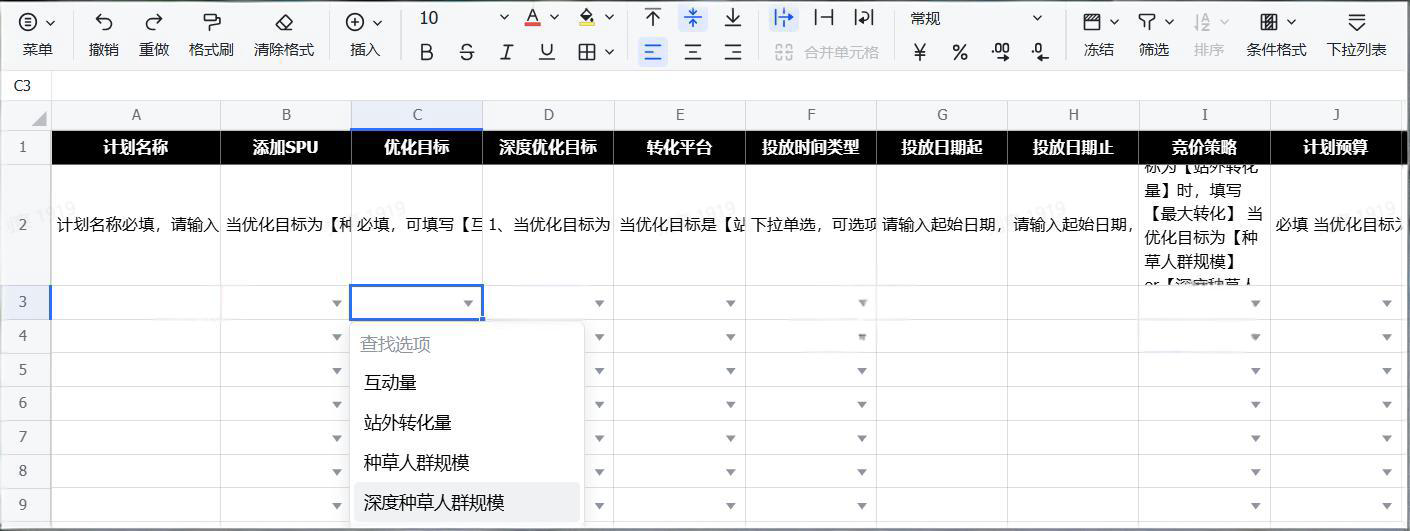 #### **功能2:智能数据读取与验证** 从飞书表格读取数据后,系统会进行多层验证: ```java // 第一层:基础字段验证 if (StringUtils.isBlank(campaignName)) { errors.add("计划名称不能为空"); } // 第二层:关键词数据验证 if (StringUtils.isBlank(keywordTemplateDTO.getKeyword())) { errors.add("关键词不能为空"); } // 第三层:人群包数据验证 if (!RedBookExcelUtil.isNumeric(premiumTemplateDTO.getRatio())) { errors.add("溢价系数必须是数字"); } ``` **亮点**: - ⚡ **前置验证**:在调用API前完成所有校验,避免浪费API调用 - 📍 **精准定位**:错误信息直接回写到对应的表格行,方便修改 - 🔄 **增量处理**:已经创建成功的数据不会重复处理 #### **功能3:数据分组合并** 这是系统的核心算法,解决了一个关键问题:**如何将表格中的扁平数据转换为广告API需要的层级结构?** ```java private List<RedBookCreateCascadeInfoDTO> mergeCascadeInfosByGroup( List<RedBookCreateCascadeInfoDTO> cascadeInfoDTOS) { // 第一步:按计划名称分组 Map<String, List<RedBookCreateCascadeInfoDTO>> campaignGroups = cascadeInfoDTOS.stream() .collect(Collectors.groupingBy( cascadeInfo -> cascadeInfo.getCampaign().getCampaignName() )); // 第二步:在每个计划内,按单元名称分组 Map<String, List<RedBookUnitWithCreativeDTO>> unitGroups = allUnitWithCreatives.stream() .collect(Collectors.groupingBy( unitWithCreative -> unitWithCreative.getUnit().getUnitName() )); // 第三步:合并创意数据 // ... } ``` **为什么需要分组合并?** 假设表格中有这样的数据: | 计划名称 | 单元名称 | 创意名称 | 创意素材 | |---------|---------|---------|---------| | 春季促销 | 北京地区 | 创意A | 图片A | | 春季促销 | 北京地区 | 创意B | 图片B | | 春季促销 | 上海地区 | 创意C | 图片C | API需要的结构是: ```json { "campaign": "春季促销", "unitWithCreativeList": [ { "unit": "北京地区", "creativityList": ["创意A", "创意B"] }, { "unit": "上海地区", "creativityList": ["创意C"] } ] } ``` 通过分组合并算法,系统自动将扁平的表格数据转换为层级结构,一次API调用就能创建完整的计划。 #### **功能4:结果回写与状态追踪** 广告创建完成后,系统会自动将结果回写到飞书表格: ```java // 回写成功数据 writeExcelDTO.setCampaignId(String.valueOf(campaignId)); writeExcelDTO.setUnitId(String.valueOf(unitId)); writeExcelDTO.setCreativityId(String.valueOf(creativityId)); writeExcelDTO.setErrMsg(" "); // 空格表示成功 // 回写失败数据 writeExcelDTO.setErrMsg("落地页不存在,请检查落地页名称"); ``` **亮点**: - ✅ **实时反馈**:创建结果立即回写到表格,无需手动查询 - 🔍 **详细错误信息**:失败的数据会显示具体的错误原因 - 📊 **统计汇总**:自动统计成功数、失败数、总数 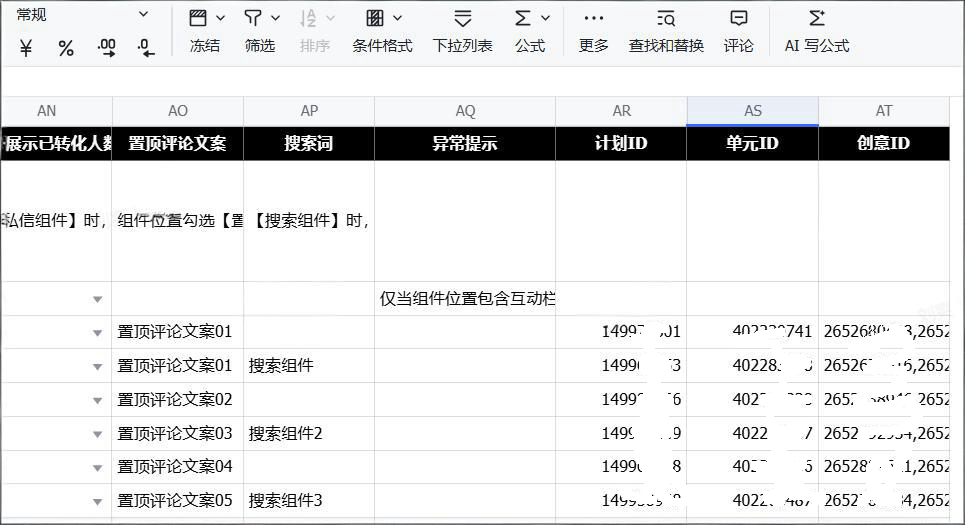 #### **功能5:数据映射与重试机制** 系统会保存每一行数据的映射关系: ```java AdAssistantMetaDataMapping mapping = new AdAssistantMetaDataMapping(); mapping.setMetaId(batchId); mapping.setRowNum(cascadeInfoDTO.getRow()); mapping.setUniqueId(cascadeInfoDTO.getUniqueId()); mapping.setRowData(JSONObject.toJSONString(cascadeInfoDTO)); mapping.setStatus(0); // 0-待处理, 1-成功, 2-失败 ``` **用途**: - 🔄 **支持重试**:失败的数据可以修改后重新执行 - 📜 **审计追溯**:记录每次操作的完整数据 - 🚫 **防重复**:已成功的数据不会重复创建 ## 三、技术亮点 ### 3.1 优雅的异常处理 系统采用了分层异常处理策略: ```java try { // 业务逻辑 } catch (ZrException e) { // 业务异常:记录详细日志,返回友好提示 log.error("【广告助手】创建失败. 参数: {}, 错误: {}", JSON.toJSONString(request), e.getMessage(), e); throw e; } catch (Exception e) { // 系统异常:记录堆栈,清理资源 removeFsTable(sheetId, keywordSheetId, premiumSheetId); throw new ZrException("系统异常,请联系管理员"); } ``` ### 3.2 资源自动清理 使用Java的`try-with-resources`确保资源正确释放: ```java try (FsClient fsClient = FsClient.getInstance()) { fsClient.initializeClient(appId, appSecret); // 使用飞书客户端 } // 自动关闭连接 ``` ### 3.3 流式数据处理 充分利用Java 8 Stream API,代码简洁高效: ```java // 过滤出待处理的数据 redBookExcelList = redBookExcelList.stream() .filter(item -> { Long campaignId = item.getCampaignId(); Long unitId = item.getUnitId(); String creativityId = item.getCreativityId(); // 至少有一个ID为空,说明需要处理 return campaignId == null || unitId == null || StringUtils.isBlank(creativityId); }) .collect(Collectors.toList()); ``` ### 3.4 多租户隔离 系统支持多租户,每个租户的数据完全隔离: ```java try { TenantFilterContext.set(true); // 启用租户过滤 adAssistantMeta.setTenantId(tenantId); adAssistantMetaService.save(adAssistantMeta); } finally { TenantFilterContext.clear(); // 清理上下文 } ``` ## 四、实际效果 通过这个系统,我们实现了: - ⏱️ **效率提升10倍**:原来需要2小时的批量创建工作,现在5分钟搞定 - ❌ **错误率降低90%**:自动校验避免了大部分人为失误 - 📈 **投放规模扩大**:支持单次创建500+广告计划 - 👥 **团队协作提升**:多人可同时编辑,实时查看进度 ## 五、可扩展性设计 这套架构不仅适用于小红书,还可以快速扩展到其他广告平台: ```java // 通过注解标识平台 @AdAssistantPlatform(AdPlatformEnum.RED_BOOK) @AdPlatformService(AdPlatformEnum.RED_BOOK) public class AdRedBookAssistantProcessorServiceImpl implements AdAssistantBaseService { // ... } // 新增平台只需实现相同接口 @AdAssistantPlatform(AdPlatformEnum.TIKTOK) public class AdTikTokAssistantProcessorServiceImpl implements AdAssistantBaseService { // ... } ``` ## 六、总结与展望 这个案例展示了**技术如何真正为业务赋能**: 1. 🎯 **从用户视角出发**:选择飞书表格作为交互界面,而不是开发复杂的管理后台 2. 🏗️ **架构设计合理**:分层清晰,职责明确,易于维护和扩展 3. 🔒 **注重稳定性**:完善的异常处理、数据校验、重试机制 4. 📊 **可观测性强**:详细的日志记录,便于问题排查和性能优化 **未来优化方向**: - 📈 数据分析增强:自动生成广告投放效果分析报告 --- **技术栈** - 后端:Java 8 + Spring Boot + MyBatis Plus - 飞书集成:Feishu Open API + 自研封装SDK - 广告平台:小红书营销API - 架构模式:微服务 + 策略模式 + 模板方法模式 **关键代码行数:1074行** **核心逻辑:数据分组合并、增量同步、错误追踪** --- *如果你的团队也在做营销自动化,或者对这套解决方案感兴趣,欢迎留言交流!* *代码即生产力,技术即竞争力。用好工具,事半功倍!💪*